7. Clustering
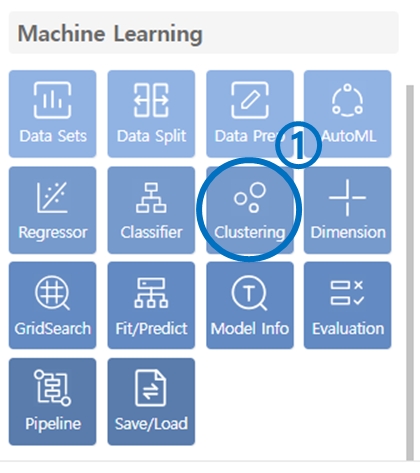
Click on Clustering under the Machine Learning category.
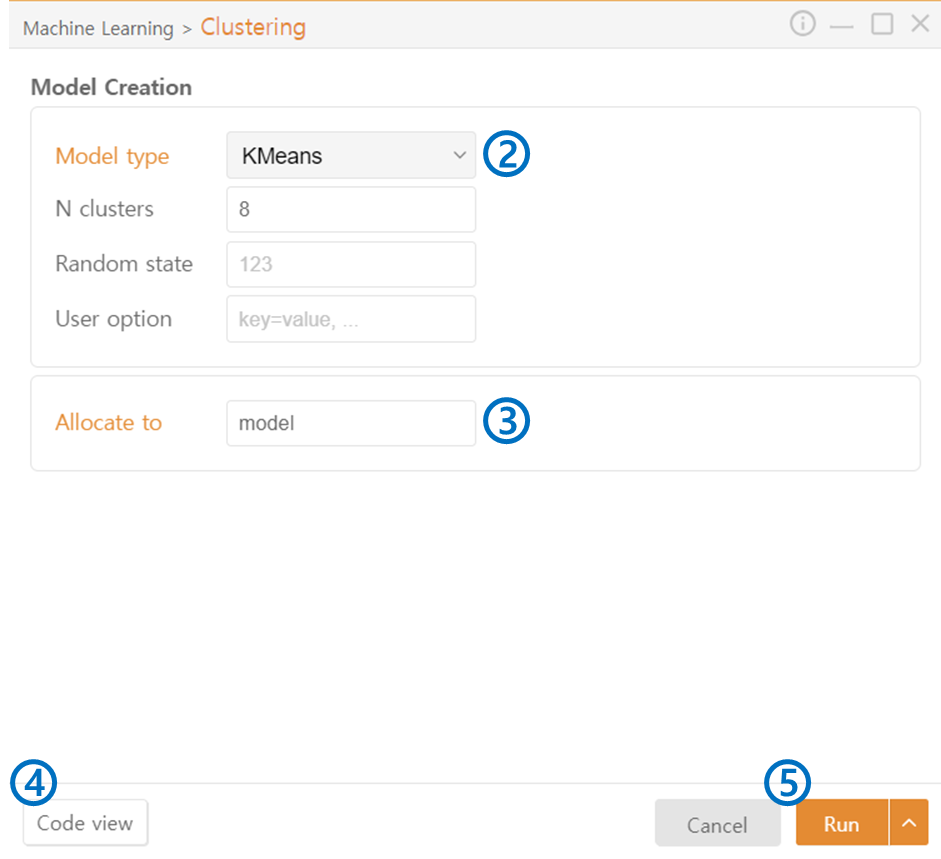
Model type: Select the type of Model you want to use.
Allocate to: Specify the variable name to assign to the generated model.
Code view: Preview the generated code.
Run: Execute the code.
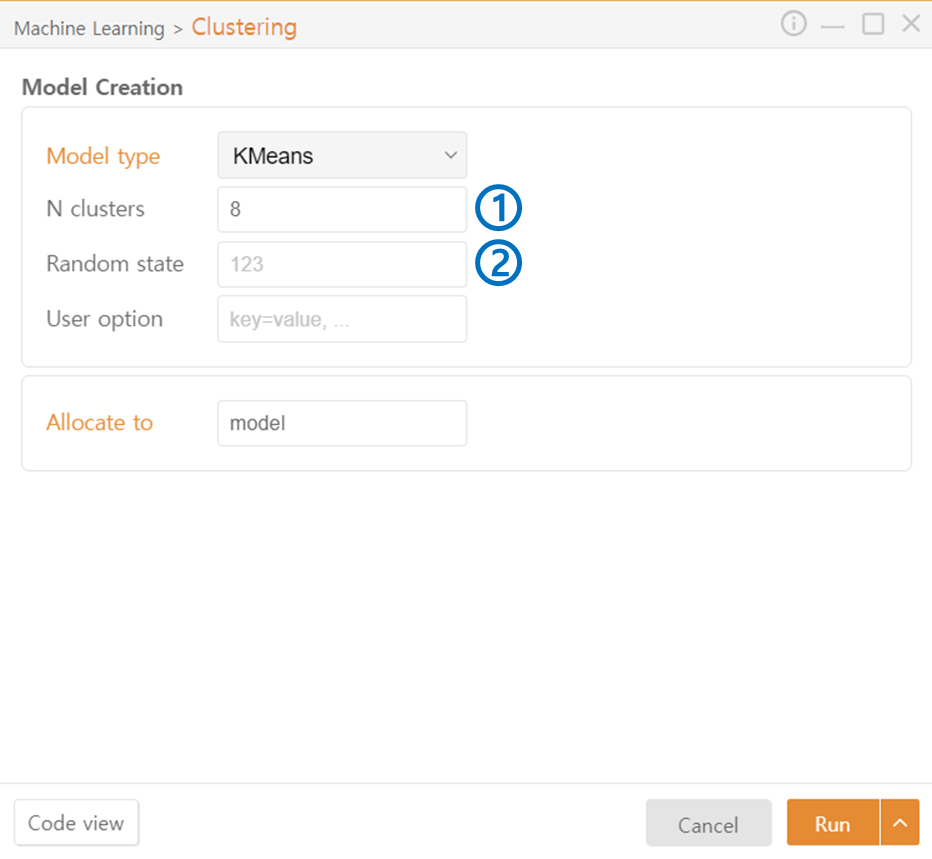
KMeans / AgglomerativeClustering
N clusters: Specify the number of clusters to be generated.
Random state: Set the seed value for the random number generator.
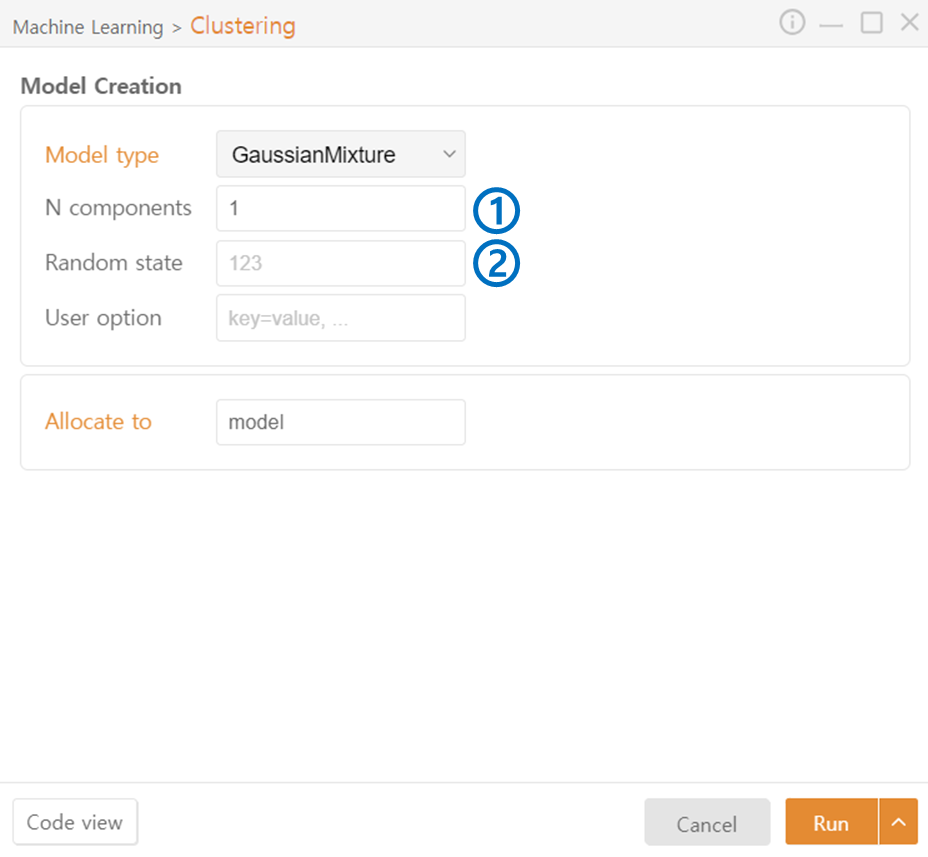
GaussianMixture
N components: Specify the number of Gaussian distributions to be used by the model to describe the data, determining how many clusters the data will be divided into.
Random state: Set the seed value for the random number generator.
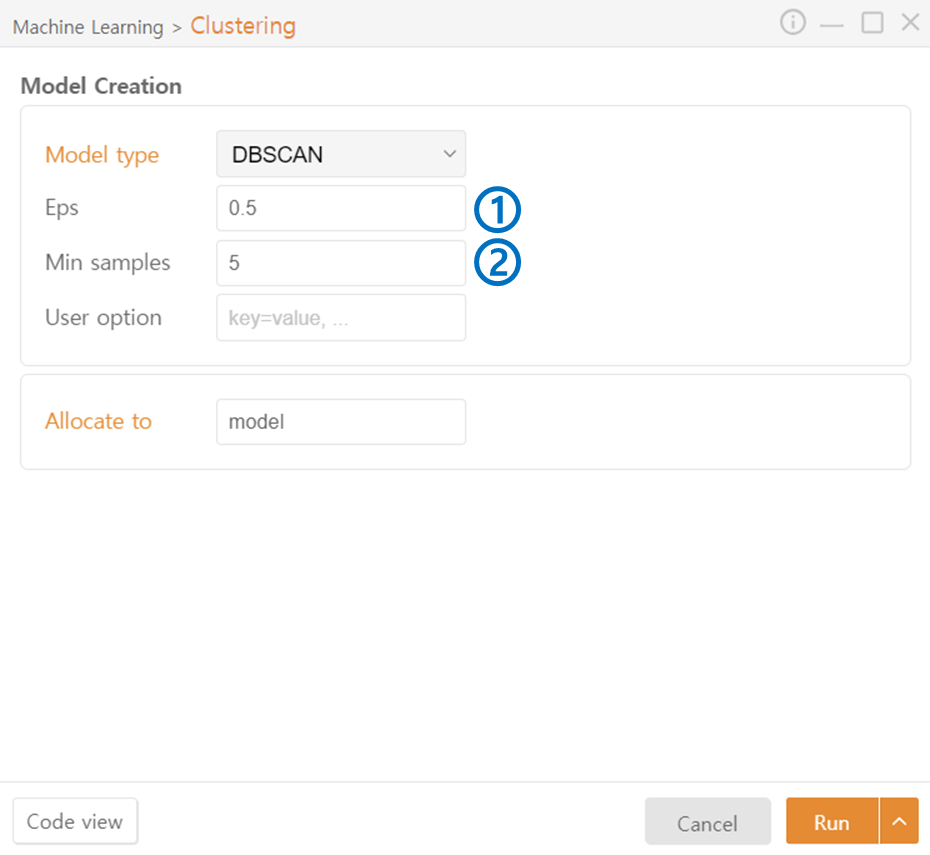
DBSCAN
Eps (Epsilon): Specify the maximum distance (radius) for forming clusters.
Min samples: Specify the minimum number of neighboring data points required for a point to be recognized as a cluster.
Last updated