
3. Data Prep
Click on Data Prep in the Machine Learning category.
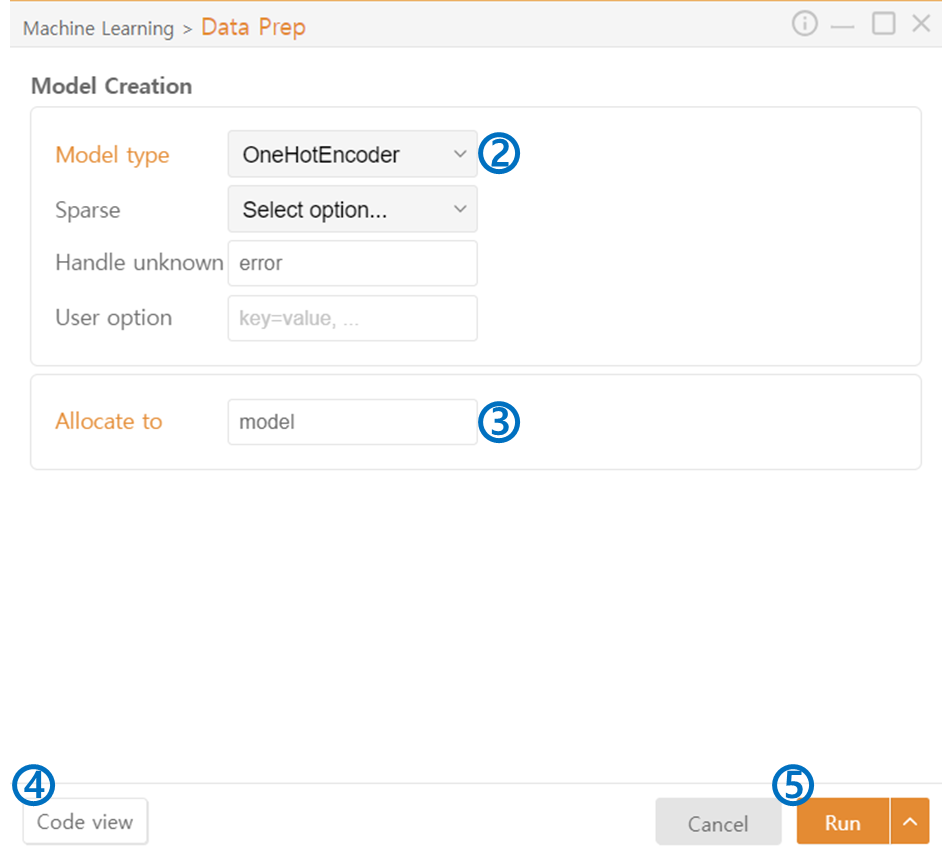
Model Type: You can perform various preprocessing tasks:
Encoding
Scaling
ETC
Allocate to: Assign variable names for the model to perform the selected preprocessing tasks.
Code View: Preview the code that will be output.
Run: Execute the code.
Last updated